- Sphere Engine overview
- Compilers
- Overview
- API
- Widgets
- Resources
- Problems
- Overview
- API
- Widgets
- Handbook
- Resources
- Containers
- Overview
- Glossary
- API
- Workspaces
- Handbook
- Resources
- RESOURCES
- Programming languages
- Modules comparison
- Webhooks
- Infrastructure management
- API changelog
- FAQ
Some popular evaluation process schemas are available in the Sphere Engine Containers out of the box. For example, assessing projects with unit tests are often done by analyzing a unit test report. For various console applications designed for IO processing, it's characteristic to feed an app with some data and compare generated output data with expected output data. Sphere Engine Containers utilities cover that in a very convenient fashion.
In this document, we will discuss all built-in schemas and provide you with informative examples. There are four categories of built-in schemas:
- Evaluators - for carrying out the whole evaluation process, from combining partial results up to the final result; evaluators are composed as a chain of support tools: validator, converter, and grader,
- Validators - support tools responsible for checking validity of intermediate execution results,
- Converters - support tools responsible for unifying validated intermediate results into the final tests report,
- Graders - support tools responsible for establishing the final result.
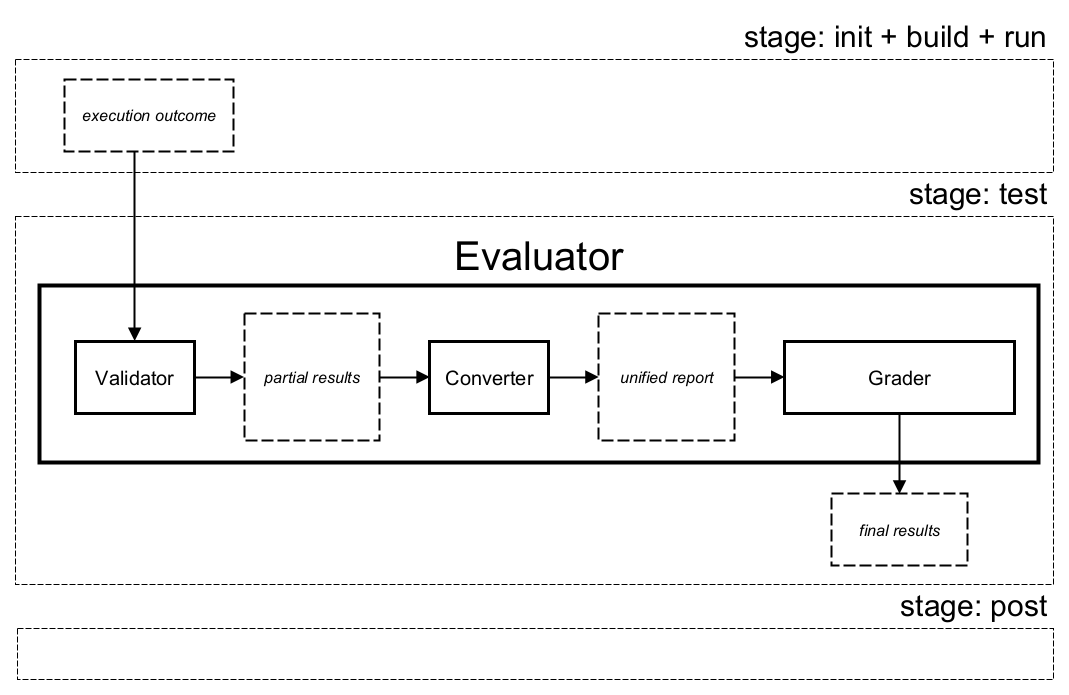
Evaluators
Evaluator is a utility that carries out the whole evaluation process taken in the test stage of the scenario.
It combines all necessary steps:
- validation of the
runstage outcome (Validator support tool), - aggregation of the partial results (Converter support tool),
- final assessment (Grader support tool).
The diagram below presents the role and place of evaluators in the scenario execution process.
Evaluator for unit tests UnitTestsEvaluator
This evaluator is designed to assess a project execution based on the result of the unit testing procedure. By default, it uses the following support tools:
XUnitValidator- for validating the unit tests report,- the unit tests report is expected to be compatible with
xUnitXML schema (e.g.,jUnitorPHPUnit), - the unit tests report should be located in the default location, so
se_utils.environment.path.unit_tests_report(for Python module) or$SE_PATH_UT_REPORT_PATH(for CLI),
- the unit tests report is expected to be compatible with
XUnitConverter- for converting the unit tests report into final tests report,- the unit tests report is expected to be compatible with
xUnitXML schema (e.g.,jUnitorPHPUnit), - the unit tests report should be located in the default location, so
se_utils.environment.path.unit_tests_report(for Python module) or$SE_PATH_UT_REPORT_PATH(for CLI), - each entry from the unit tests report will be transferred to final tests report in a unified format,
- the unit tests report is expected to be compatible with
PercentOfSolvedTestsGrader- for summarizing entries from the final tests report,- execution is successful (
status=OK) if at least one test passes; otherwise it is unsuccessful (status=FAIL), - the final score is a percentage of passed tests.
- execution is successful (
Python example using defaults:
from se_utils.evaluator import UnitTestsEvaluator
UnitTestsEvaluator().run()CLI example using defaults:
#!/bin/bash
se_utils_cli evaluate UnitTestsEvaluatorPython example with custom settings:
from se_utils.evaluator import UnitTestsEvaluator
from se_utils.validator import XUnitValidator
from se_utils.converter import XUnitConverter
from se_utils.grader import AtLeastOneTestPassedGrader
custom_ut_report_path='~/workspace/my_report.xml'
UnitTestsEvaluator(
validator=XUnitValidator(ut_report_path=custom_ut_report_path),
converter=XUnitConverter(ut_report_path=custom_ut_report_path),
grader=AtLeastOneTestPassedGrader,
).run()CLI example with custom settings:
#!/bin/bash
se_utils_cli evaluate Evaluator \
--grader "AtLeastOneTestPassedGrader"Resources:
Evaluator input/output tests IOEvaluator
This evaluator is designed to assess a project execution by comparing an output data generated during project execution with expected output data. By default, it uses the following support tools:
IgnoreExtraWhitespacesValidator- for comparing output data files,- files are considered matching with each other if they are the same up to additional white spaces (i.e., spaces, tabulations, carriage returns, and new lines),
- output data generated during project execution is expected to be located in the default location for
runstage standard output data, sose_utils.stage.run_stage.stdout_path(for Python module) or$SE_PATH_STAGE_RUN_STDOUT(for CLI), - model output data is expected to be located in the default test case location, so in the file
0.outin the directory accessible byse_utils.environment.path.test_cases(for Python module) or$SE_PATH_TEST_CASES(for CLI),
IOConverter- for creating the final tests report based on the result of validation,- the output from validator is consumed and analyzed to create the final result with a single test entry,
- if the validation is successful, then the test is marked as successful,
- if the validation is not successful, then the test status depends on the information from validator output,
- it can be either
FAIL,TLE(time limit exceeded),RE(run-time error), orBE(build error),
- it can be either
AtLeastOneTestPassedGrader- for summarizing entries from the final tests report,- execution is successful (
status=OK) if the test was successful; otherwise it is unsuccessful (status=FAIL).
- execution is successful (
Python example using defaults:
from se_utils.evaluator import IOEvaluator
IOEvaluator().run()CLI example using defaults:
#!/bin/bash
se_utils_cli evaluate IOEvaluatorPython example with custom settings:
from se_utils.evaluator import IOEvaluator
from se_utils.validator import IgnoreExtraWhitespacesValidator
path_user_output = '/home/user/workspace/out.txt'
path_model_output = '/home/user/workspace/.sphere-engine/out.txt'
IOEvaluator(
validator=IgnoreExtraWhitespacesValidator(path_user_output, path_model_output),
).run()CLI example with custom settings:
#!/bin/bash
DEFAULT_USER_OUTPUT_PATH="$SE_PATH_STAGE_RUN_STDOUT"
DEFAULT_TEST_OUTPUT_PATH="$SE_PATH_TEST_CASES/0.out"
USER_OUTPUT_PATH="~/workspace/out.txt"
TEST_OUTPUT_PATH="~/workspace/.sphere-engine/out.txt"
# copy output files to the default locations
cp $USER_OUTPUT_PATH $DEFAULT_USER_OUTPUT_PATH
cp $TEST_OUTPUT_PATH $DEFAULT_TEST_OUTPUT_PATH
se_utils_cli evaluate IOEvaluator \
--validator "IgnoreExtraWhitespacesValidator"Resources:
Validators
Validator is a utility responsible for checking a validity of intermediate results usually obtained during the
run stage of the scenario's execution. It is rather incorporated as a support tool for evaluators, but it can also
be used independently, if necessary.
Validator for unit tests XUnitValidator
This validator is designed for checking validity of a unit test report. It checks the following:
- if the report file exist,
- by default the unit test report is expected to be located in the default file, so
se_utils.environment.path.unit_tests_report(for Python module) or$SE_PATH_UT_REPORT_PATH(for CLI), - alternatively for Python module, the
XUnitValidatorclass can be initialized with aut_report_pathparameter defining different location,
- by default the unit test report is expected to be located in the default file, so
- if the report is compatible with
xUnitXML schema (e.g.,jUnitorPHPUnit).
Python example using defaults:
from se_utils.validator import XUnitValidator
validator = XUnitValidator()
validation_output = validator.validate()CLI example using defaults:
#!/bin/bash
se_utils_cli validate XUnitValidatorPython example with custom settings:
from se_utils.validator import XUnitValidator
my_ut_report_path='/home/user/workspace/ut_report.xml'
validator = XUnitValidator(ut_report_path=my_ut_report_path)
validation_output = validator.validate()CLI example with custom settings:
#!/bin/bash
MY_UT_REPORT_PATH="~/workspace/ut_report.xml"
cp $MY_UT_REPORT_PATH $SE_PATH_UT_REPORT_PATH
se_utils_cli validate XUnitValidatorResources:
Validator for comparing outputs IgnoreExtraWhitespacesValidator
This validator is designed for comparing for comparing two files. Usually one of these files is an output data
generated during project run stage, and the second one is model output data that is expected. It checks the following:
- both files should exist in their default locations,
- output data generated during project execution is expected to be located in the default location for
runstage standard output data, sose_utils.stage.run_stage.stdout_path(for Python module) or$SE_PATH_STAGE_RUN_STDOUT(for CLI), - alternatively for Python module, the
IgnoreExtraWhitespacesValidatorclass can be initialized with aprogram_outputparameter defining different location for execution output data, - model output data is expected to be located in the default test case location, so in the file
0.outin the directory accessible byse_utils.environment.path.test_cases(for Python module) or$SE_PATH_TEST_CASES(for CLI), - alternatively for Python module, the
IgnoreExtraWhitespacesValidatorclass can be initialized with atest_case_outputparameter defining different location for model output data,
- output data generated during project execution is expected to be located in the default location for
- files are considered matching with each other if they are the same up to additional white spaces (i.e., spaces, tabulations, carriage returns, and new lines),
Python example using defaults:
from se_utils.validator import IgnoreExtraWhitespacesValidator
validator = IgnoreExtraWhitespacesValidator()
validation_output = validator.validate()CLI example using defaults:
#!/bin/bash
se_utils_cli validate IgnoreExtraWhitespacesValidatorPython example with custom settings:
from se_utils.validator import IgnoreExtraWhitespacesValidator
path_user_output = '/home/user/workspace/out.txt'
path_model_output = '/home/user/workspace/.sphere-engine/out.txt'
validator = IgnoreExtraWhitespacesValidator(path_user_output, path_model_output)
validation_output = validator.validate()CLI example with custom settings:
#!/bin/bash
DEFAULT_USER_OUTPUT_PATH="$SE_PATH_STAGE_RUN_STDOUT"
DEFAULT_TEST_OUTPUT_PATH="$SE_PATH_TEST_CASES/0.out"
USER_OUTPUT_PATH="~/workspace/out.txt"
TEST_OUTPUT_PATH="~/workspace/.sphere-engine/out.txt"
# copy output files to the default locations
cp $USER_OUTPUT_PATH $DEFAULT_USER_OUTPUT_PATH
cp $TEST_OUTPUT_PATH $DEFAULT_TEST_OUTPUT_PATH
se_utils_cli validate IgnoreExtraWhitespacesValidatorResources:
Converters
Converter (also Test Result Converter) is a utility responsible for unifying intermediate results obtained
during the run stage of the scenarios's execution (and potentially also outcome of validation process). Similarly to
validators, it is usually used as a support tool for evaluators. It can also be used independently, if necessary. The
main task of converters is producing final tests reports that can be later consumed by graders.
Note: The final tests report is also available as one of the streams produced during scenario's execution. The technical reference covering a specification of the final tests report is covered in detail in a separate document.
Converter for unit tests XUnitConverter
This converter is designed for converting the unit tests report into the final tests report. The following rules apply:
- the unit tests report is expected to be compatible with
xUnitXML schema (e.g.,jUnitorPHPUnit), - the unit tests report should be located in the default location, so
se_utils.environment.path.unit_tests_report(for Python module) or$SE_PATH_UT_REPORT_PATH(for CLI),- alternatively for Python module, the
XUnitConverterclass can be initialized with aut_report_pathparameter defining different location for the unit tests report,
- alternatively for Python module, the
- each entry from the unit tests report will be transferred to final tests report in a unified format.
Python example using defaults:
from se_utils.converter import XUnitConverter
converter = XUnitConverter()
converter.convert()CLI example using defaults:
#!/bin/bash
se_utils_cli convert XUnitConverterPython example with custom settings:
from se_utils.converter import XUnitConverter
user_junit_report = '/home/user/workspace/maven_project/target/report.xml'
converter = XUnitConverter(ut_report_path=user_junit_report)
converter.convert()CLI example with custom settings:
#!/bin/bash
USER_JUNIT_REPORT_PATH="~/workspace/maven_project/target/report.xml"
# copy unit tests report to the default location
cp $USER_JUNIT_REPORT_PATH $SE_PATH_UNIT_TESTS_REPORT
se_utils_cli convert XUnitConverterResources:
Converter for input/output tests IOConverter
This converter is designed for creating the final tests report based on the result of file validation. The following rules apply:
- the output from validator is consumed and analyzed to create the final result with a single test entry,
- for Python module, the content of validation output should be provided as a
validator_outputparameter during theIOConverterclass initialization, - for CLI, the content of validation output should be provided as standard input data,
- if the output from validator is not provided, then only the current value of final
statusis taken into account,
- for Python module, the content of validation output should be provided as a
- if the validation is successful, then the test is marked as successful,
- if the validation is not successful, then the test status depends on the information from validator output,
- it can be either
FAIL,TLE(time limit exceeded),RE(run-time error), orBE(build error).
Python example using defaults:
from se_utils.converter import IOConverter
converter = IOConverter()
converter.convert()CLI example using defaults:
#!/bin/bash
se_utils_cli convert IOConverterPython example with custom settings:
import json
from se_utils.converter import IOConverter
validation_output_path='/home/user/workspace/validation.json'
with open(validation_output_path) as f:
validation_output_data = json.load(f)
converter = IOConverter(validator_output=validation_output_data)
converter.convert()CLI example with custom settings:
#!/bin/bash
VALIDATION_OUTPUT_PATH='~/workspace/validation.json'
se_utils_cli convert IOConverter < $VALIDATION_OUTPUT_PATHResources:
Graders
Grader is a utility responsible for establishing the final result based on the final tests report produced by the
converter. The final result is usually a compilation of the final status (e.g., OK that states for a
success), the score, and the execution time.
Similarly to validators and converters, grader is also usually used as a support tool of the for evaluators. As for the others, it can also be used independently, if necessary.
Grader PercentOfSolvedTestsGrader
This grader is designed for summarizing entries from the final tests report in the following way:
- execution is successful (
status=OK) if at least one test passes; otherwise it is unsuccessful (status=FAIL), - the final score is a percentage of passed tests,
- the final execution time is not set nor overridden.
Python example using defaults:
from se_utils.converter import PercentOfSolvedTestsGrader
grader = PercentOfSolvedTestsGrader()
grader.grade()CLI example using defaults:
#!/bin/bash
se_utils_cli grade PercentOfSolvedTestsGraderResources:
Grader AtLeastOneTestPassedGrader
This grader is designed for summarizing entries from the final tests report in the following way:
- execution is successful (
status=OK) if at least one test passes; otherwise it is unsuccessful (status=FAIL), - the final score is not set nor overridden,
- the final execution time is not set nor overridden.
Python example using defaults:
from se_utils.converter import AtLeastOneTestPassedGrader
grader = AtLeastOneTestPassedGrader()
grader.grade()CLI example using defaults:
#!/bin/bash
se_utils_cli grade AtLeastOneTestPassedGraderResources:
Grader WeightedScoreTestsGrader
This grader is designed for summarizing entries from the final tests report in the following way:
- execution is successful (
status=OK) if the final score is positive (score>=0); otherwise, it is unsuccessful (status=FAIL), - the final score is a sum of weights for all the tests (see details below). You can assign weights to all successful or failed tests depending on the use case. Grader supports granular-level configuration for each test case,
- the final execution time is not set nor overridden.
We wrote a detailed guide describing advanced use cases with the weighted grader. If you want more details then example below, we strongly recommend reading the guide.
Python example using defaults:
from se_utils.grader import WeightedScoreTestsGrader, TestWeightSelector
# Weights won't be loaded from the project config
# We state them explicitly
# To use project config, please use:
# grader = WeightedScoreTestsGrader()
#
grader = WeightedScoreTestsGrader([
TestWeightSelector(name="testCaseFoo", weight=9),
TestWeightSelector(classname="barClass", weight=5),
TestWeightSelector(classname="fooClass", weight=12),
TestWeightSelector(classname="mooClass", name="testCaseFoo", weight=90),
])
grader.grade()CLI example using defaults:
#!/bin/bash
# Weights will be loaded from the project config, from the "scenarios.scenario_name.tests_weights" field
se_utils_cli grade WeightedScoreTestsGraderHow the final score is calculated:
- For each test find a first selector that matches that test case and assign a specified weight for that selector. For
ease of usage if no selector is found, then assign
1for a successful test case and0otherwise, - Sum up all the weights,
- If the sum is positive, the final status is
OK(FAILotherwise).
A selector is an object that specifies the following properties:
classname- matches the class name of the test."*"matches any class name. By default"*"is used if the property is not explicitly specified,name- matches the name of the test case."*"matches any name. By default"*"is used if the property is not explicitly specified,status- matches the status of the test."*"to match any test case status. This property is handy when you want to assign negative scores to the tests that fail. The status of the test can befailure,okorerror. ("ok"is the default value),weights- weight for the test case that matches that selector. This is a required field without a default value.
Example #1: Basic configuration
Selector configuration can be specified in scenarios.scenario_name.tests_weights field of the project config:
{
"version": 2.1,
"custom": {
"sphere_engine_example_version": 1.0
},
"scenarios": {
"test": {
"tests_weights": [
{
// This selector matches any test case called testCaseFoo
// even if there are multiple tests called testCaseFoo in various test classes
"name": "testCaseFoo",
"weight": 9
// classname is missing so by default "*" is used
},
{
// This selector matches all tests in class barClass
"classname": "barClass",
"weight": 5
// name is missing so by default "*" is used
},
{
// This selector matches all tests in class fooClass
"classname": "fooClass",
"weight": 12
// name is missing so by default "*" is used
},
{
// This matches only testCaseFoo test case in class mooClass
"classname": "mooClass",
"name": "testCaseFoo",
"weight": 90
}
],
"stages": {
"build": {
"command": "bash -c 'mkdir -p _build && cd _build && cmake .. && make'",
"timeout": 120
},
"run": {
"command": "bash -c 'GTEST_OUTPUT=\"xml:$RUNTIME/report.xml\" ./_build/test ; exit 0'"
},
"test": {
"command": "se_utils_cli evaluate UnitTestsEvaluator --grader PercentOfSolvedTestsGrader --converter XUnitConverter"
}
},
"output": {
"type": "tests",
"path": "/sphere-engine/runtime/report.json"
}
}
},
"files": {
"open_at_startup": [
"main.cpp"
]
}
}For the example above we assume that you use the following configuration and test results in xUnit format:
se_utils_cli evaluate UnitTestsEvaluator \
--grader "WeightedScoreTestsGrader" \
--converter "XUnitConverter"For xUnit test case:
<testcase name="barTestCase" classname="barClass" time="0.285"/>For xUnit test case:
<testcase name="testCaseFoo" classname="mooClass" time="0.121"/>For xUnit test case:
<testcase name="testCaseMoo" classname="zeeClass" time="0.913"/>If you want to learn more about advanced use cases, we recommend reading our detailed guide on the weighted grader.
Example #2: Empty configuration
By default (so the experience is compatible with other graders) graders use fallback weights equal to 1. Users can
create additional tests and they will be included in the score as well. All failed tests have weights equal to 0:
{
"scenarios": {
"test": {
"tests_weights": []
}
}
}Example #3: Use only defined tests and ignore user-written cases
By looking at the example above, you might want to score only defined tests and ignore anything else. This is useful if
you have very simple example tests that you want leave not-rated by default. To achieve that behavior we explicitly add
all class names and test case names and append rule to assign weight 0 for anything else:
{
"scenarios": {
"test": {
"tests_weights": [
{
"classname": "SomeClass",
"name": "case1",
"weight": 5
},
{
"classname": "SomeClass",
"name": "case2",
"weight": 9
},
{
"weight": 0
}
]
}
}
}0 to succeeding tests that were not directly specified.
Example #4: Using negative scores for failed tests
We can assign a negative score to any test that fails. To that point negative final scores weren't possible. We append
a rule that matches any test case that fails. Note that by default, status will be set to ok if not explicitly
stated. This means that if we write the following configuration:
{
"scenarios": {
"test": {
"tests_weights": [
{
"classname": "SomeClass",
"name": "testCase",
"weight": 9
},
{
"status": "failure",
"weight": -1
}
]
}
}
}It's equivalent to:
{
"scenarios": {
"test": {
"tests_weights": [
{
"classname": "SomeClass",
"name": "testCase",
"weight": 9,
"status": "ok"
},
{
"classname": "*",
"name": "*",
"status": "failure",
"weight": -1
}
]
}
}
}This means that if the test case fails:
<testcase name="testCase" classname="SomeClass" time="0.113"/>Then we still assign weight -1 (the first rule does not match).
Example #4: Using varying negative scores for failed tests
We can define the same granular weights for failed tests as for those that pass. Extending the example above, we can write:
{
"scenarios": {
"test": {
"tests_weights": [
{
"classname": "SomeClass",
"name": "testCase",
"weight": 9
},
{
"classname": "SomeClass",
"name": "testCase",
"weight": -12,
"stauts": "failure"
},
{
"status": "failure",
"weight": -1
}
]
}
}
}The following configuration will:
- assign weight
9to testCase from SomeClass if it passes (first selector) or-12otherwise (second selector), - assign a default weight of
1to any other passing test, - assign a weight of
-1(last selector) to any other failed test.
If you want to learn more about advanced use cases, we recommend reading our detailed guide on the weighted grader.
Resources: